Reducing LLM API Spend by Leveraging On-Prem Models with Oblix
⚙️ Use Case: Reducing LLM API Spend by Leveraging On-Prem Models with Oblix
As enterprises embrace LLMs for internal tools, customer support automation, and AI copilots, many quickly run into the cost and control problem.
Here's what that typically looks like:
You start building with third-party APIs like OpenAI, Anthropic, or Cohere. It's fast and powerful — but it gets expensive quickly, especially as usage scales.
At the same time, your company may already have on-prem GPU clusters or private inference endpoints — running open models like LLaMA 3, Mistral, or Mixtral.
So why is every query still hitting the cloud?
The Problem: One-Size-Fits-All Routing
Today's LLM apps are hardcoded to use one model or provider. Even if:
- The query is simple
- The on-prem model is good enough
- The data is sensitive
- The cost savings would be massive
… the prompt still gets routed to an external API — where it's billed and possibly stored.
Enter Oblix: Dynamic LLM Routing Between On-Prem & Cloud
Oblix is a lightweight orchestration layer that routes prompts intelligently between:
- On-premise models (e.g., LLaMA 3 hosted internally via Ollama, vLLM, or Triton)
- Third-party APIs (e.g., OpenAI, Anthropic, Cohere)
It deploys smart agents that monitor:
- Resource availability (is your internal cluster free?)
- Prompt complexity (does this need GPT-4 or can a distilled model handle it?)
- Connectivity (are external APIs rate-limiting or down?)
- Privacy flags (does the data need to stay in-house?)
Based on that context, Oblix decides: ➡️ Run it locally → save cost, improve privacy ➡️ Send it to cloud → when extra model power is needed
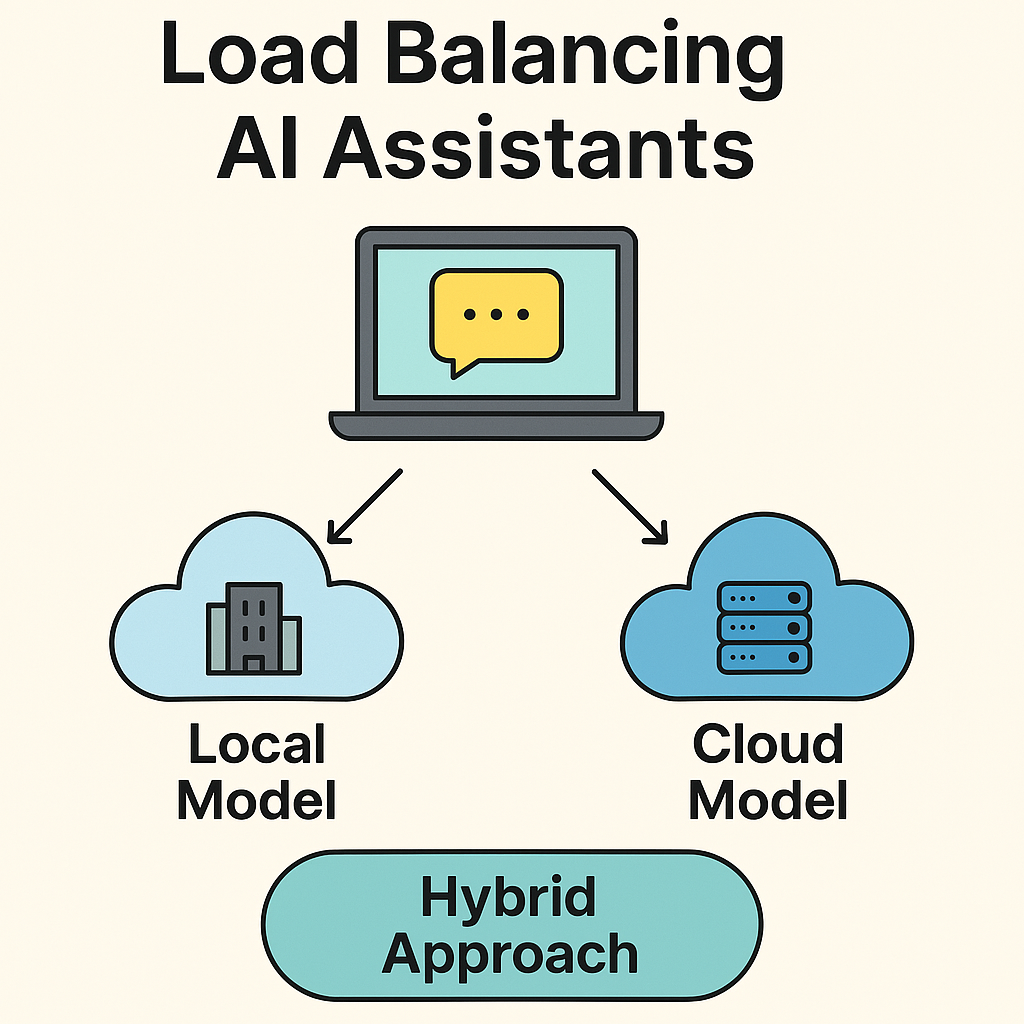
Oblix's intelligent orchestration layer routes prompts between local models and cloud APIs based on real-time conditions
Why This Matters for the Business
Without Oblix:
- Everything hits the cloud
- You pay for every token
- Sensitive data may leave your environment
With Oblix:
- You reduce cloud API usage by leveraging your existing infra
- You maintain privacy by keeping sensitive prompts internal
- You improve uptime with graceful fallback between on-prem and cloud
Who Should Use This?
If you're a company:
- Already running internal models for fine-tuned use cases
- Using OpenAI/Anthropic for fallback or complex queries
- Looking to optimize AI cost and reliability
- Navigating compliance and data governance around LLMs
Oblix helps you create a hybrid LLM stack — and orchestrates it seamlessly.
How to Get Started
We support:
- Open source models via Ollama, vLLM, HuggingFace
- API providers like OpenAI, Anthropic, Cohere
- Lightweight agents for real-time monitoring and smart prompt routing
We're currently onboarding enterprise dev teams exploring hybrid LLM deployments.
👉 oblix.ai
Let's help your AI stack run smarter — not just bigger.
Join Our Community!
Have questions about implementing a hybrid LLM strategy in your organization? Want to connect with other developers using Oblix? Join our thriving Discord community where you can get help, share your projects, and collaborate with the Oblix team.
Join the Oblix Discord server →
About Oblix
Oblix is an AI orchestration SDK that seamlessly routes between local and cloud models based on connectivity, system resources, and business requirements. It provides a unified interface for AI model execution, making your applications more resilient, cost-effective, and privacy-conscious.